이번 포스팅은 다음 논문들의 내용을 이용하여 정리하였습니다.
- SphereFace: Deep Hypersphere Embedding for Face Recognition
- CosFace: Large Margin Cosine Loss for Deep Face Recognition
Intro
위 두개의 논문은 기존에 연구되어 오던 closed-set 뿐만 아니라 open-set에서도 좋은 성능을 보이는 metric learning이라고 볼 수 있으며, contrastive loss, triplet loss, center loss와 같은 유클리드 공간으로의 매핑이 아닌 반지름 길이 1의 구의 공간으로 매핑합니다. 단순한 거리가 아닌 각도를 이용해 클래스를 구분하는 방법, 즉 Cosine Similarity를 이용해 클래스를 구분하는 방법을 제시합니다.
이번 포스트는 SphereFace 이 후에 CosFace를 말씀드릴 예정입니다.
전체적인 loss 변화의 흐름을 보기 위해 Intro부분에서 오늘 다룰 loss의 기반이 되는 loss(softmax loss & modified softmax loss(Normalized version of Softmax Loss)) 2개를 먼저 간단히 말씀드리겠습니다. 이 후에 본격적으로 SphereFace에서 사용했던 Angular softmax loss 그리고 CosFace에서 사용했던 Large Margin Cosine Loss(LMCL) 순으로 설명 드리고 비교를 통해 어떤 점이 달라졌는지 정리하도록 하겠습니다.
Metric Learning 이란?
Loss에 대해서 설명하기에 앞서 metric learning에 대해서 짚고 넘어가려 합니다. 일반 classification 모델과는 다르게 metric learning은 class를 구분하기 위한 피쳐를 뽑는 방법을 학습합니다. 따라서 이전 모델에는 뒷부분에 softmax layer가 포함되어 있어 추론의 결과물로 어떤 클래스일지를 알려주게됩니다. 하지만 metric learning이 적용된 모델은 학습 부분에 CNN에 들어온 이미지가 어떤 클래스로 구분될지 학습되도록 뒷부분에 softmax layer가 포함되어 있지만, 추론에는 뒷부분의 softmax layer를 제거하고 CNN에서 통과하는 feature를 결과물로 냅니다. 그리고 verification이나 identification은 이 모델을 통과해서 추출한 feature vector의 값을 Euclidean distance를 이용해 판별하게 됩니다. 이번에 말씀드릴 Angular softmax 모델의 구조는 본 포스트 뒷부분에 나오는 실험 및 결과 파트에 추가하였습니다.
모든 metric learning의 목적은 최대화된 intra-class의 angular distance가 최소화된 inter-class의 angular distance보다 작아지게 하는 것 입니다.
Softmax & modified softmax
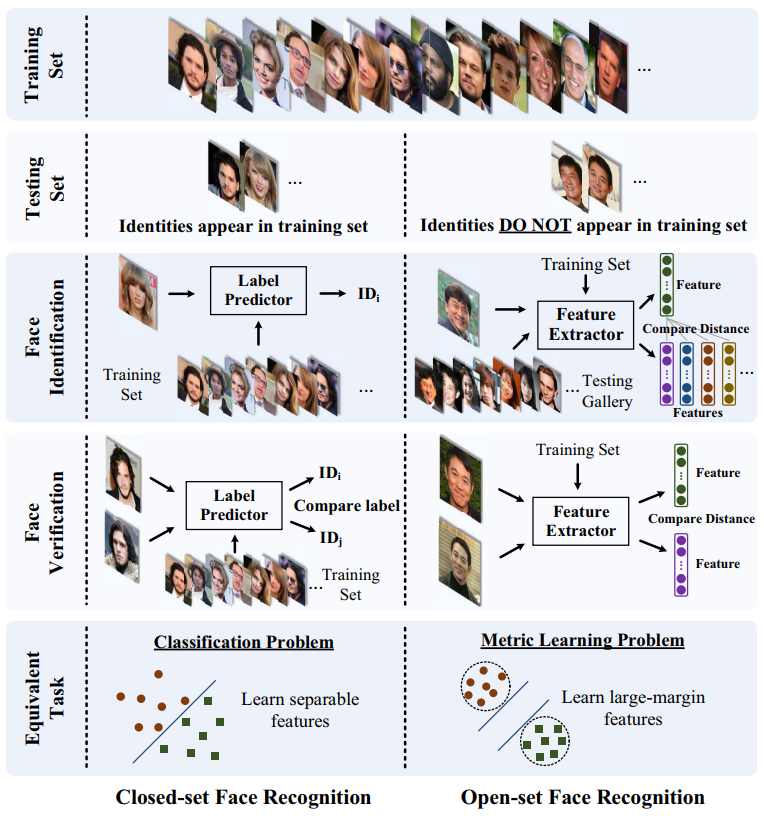
일반적인 softmax의 경우 분류할 모든 클래스와 들어온 이미지에 대해 비교해 일치할 정도에 대해 학습하는 classification 방법입니다. 위 사진에서 보이는 왼쪽 Closed-set Face Recognition이 이에 해당합니다. 일반적인 softmax는 metric learning 기법이 적용되어 있지 않습니다. 본 포스트에서는 softmax에 metric learning개념을 적용해 Open-set Face Recognition을 푸는 방법에 대해 소개합니다. cosine similarity를 이용해 metric learning을 하기 위해 cosine 함수를 softmax의 decision boundary에 적용하고 Weight와 bias를 각각 1과 0으로 normalize해 modified softmax를 사용합니다.
binary class를 구분한다고 가정했을 때, weights 와 bias 를 가진 softmax loss의 deicision boundary는 로 볼 수 있습니다. 이를 반지름이 1인 구(Sphere)로 매핑했을 때 이므로 decision boundary는 로 표현 될 수 있습니다. 따라서 만약 우리가 weights와 bias를 으로 normalize한다면 들어오는 인풋이미지 x에 대해서 각각 class의 posterior probabilities는 로 표현 할 수 있습니다. 이에따라 클래스를 구분짓는 는 와 사이의 각인 과 에 따라 결정됩니다. posterior probabilities는 , 로 표현 될 수 있고 일반적인 softmax loss는 입니다. 그리고 는 입니다. 이를 이용해 softmax를 수정하면 modified softmax loss는 이 됩니다. 이를 Normalized version of Softmax Loss(NSL)이라고도 합니다.
Body
Angular Softmax

일반적인 softmax의 loss로 학습한 후에 피쳐벡터들을 유클리드 공간으로 매핑한다면 다른 클래스의 이미지들임에도 불구하고 비슷한 위치에 매핑됩니다. 하지만 여기에 거리 개념을 도입해 같은 얼굴 혹은 다른 클래스에 대해서 학습한다면 (c)modified softmax loss 그래프에서 보이는 것처럼 다른 클래스는 명확하게 다른 공간으로 매핑되게 됩니다. 하지만 여기에서 input 이미지에 대한 피쳐벡터를 다른 클래스와의 거리를 학습할때 m과 같은 margin을 주면 그만큼의 곱 이상의 거리를 학습해 반지름 1의 구의 표면으로 매핑한다면 각 클래스를 나타내는 를 통해 더욱 분명하게 클래스를 구분할 수 있도록 CNN을 학습 할 수 있게 됩니다.
Angular-softamx loss 에선 클래스 1 과 클래스 2의 m margin을 갖는 decision boundary는 그리고 로 표현 할 수 있습니다. input 이미지 x에 대해서 class1의 이 class2의 보다 작다면 class1로 분류, 반대의 경우라면 class2로 분류합니다.
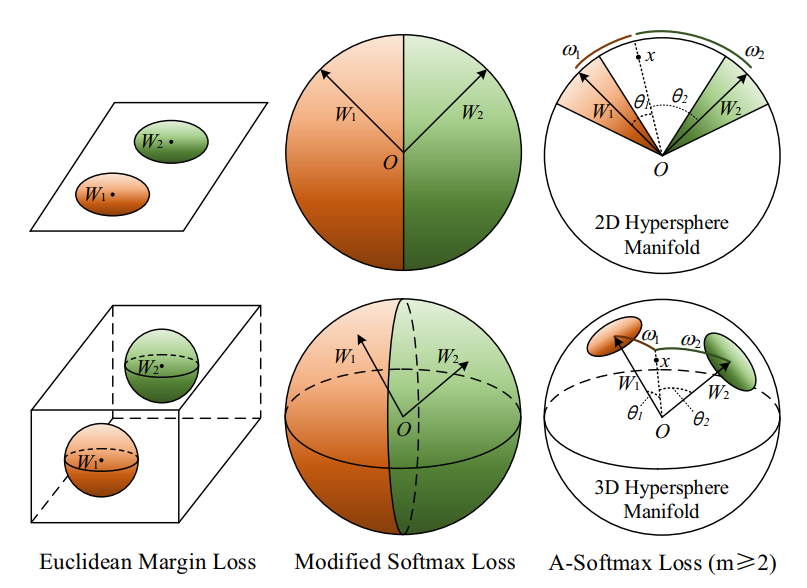 위 그래프는 Euclidean Margin Loss, Modified Softmax Loss 그리고 A-Softmax Loss가 어떤 식으로 클래스를 구분하는지에 대해 2D와 3D를 이용해 기하학적으로 표시하여 좀 더 직관적으로 나타내었습니다. FaceNet에서 사용한 triplet과 같은 Euclidean Margin Loss는 무한한 공간안에서 각각의 클래스가 자리를 잡도록 매핑합니다. Modified Softmax Loss는 margin없이 일정 경계선을 기준으로 클래스가 구분됩니다. metric learning의 특성상 이 모델을 통해 학습되지 않은 이미지를 분류하려고 한다면 추출된 피쳐벡터가 다른 클래스의 경계선을 넘어나는 경우가 생깁니다. 가장 오른쪽에 있는 A-Softmax Loss는 클래스가 1인 input 이미지 x에 대해 클래스의 각도가 클래스의 각도 보다 2배 이상이 작도록 학습합니다. 모든 모델은 학습한 데이터로 추론할 때 클래스 1은 정확하게 주황색의 공간으로, 클래스 2는 정확하게 초록색의 공간으로 매핑됩니다.
위 그래프는 Euclidean Margin Loss, Modified Softmax Loss 그리고 A-Softmax Loss가 어떤 식으로 클래스를 구분하는지에 대해 2D와 3D를 이용해 기하학적으로 표시하여 좀 더 직관적으로 나타내었습니다. FaceNet에서 사용한 triplet과 같은 Euclidean Margin Loss는 무한한 공간안에서 각각의 클래스가 자리를 잡도록 매핑합니다. Modified Softmax Loss는 margin없이 일정 경계선을 기준으로 클래스가 구분됩니다. metric learning의 특성상 이 모델을 통해 학습되지 않은 이미지를 분류하려고 한다면 추출된 피쳐벡터가 다른 클래스의 경계선을 넘어나는 경우가 생깁니다. 가장 오른쪽에 있는 A-Softmax Loss는 클래스가 1인 input 이미지 x에 대해 클래스의 각도가 클래스의 각도 보다 2배 이상이 작도록 학습합니다. 모든 모델은 학습한 데이터로 추론할 때 클래스 1은 정확하게 주황색의 공간으로, 클래스 2는 정확하게 초록색의 공간으로 매핑됩니다.
Large Margin Cosine Loss (LMCL)
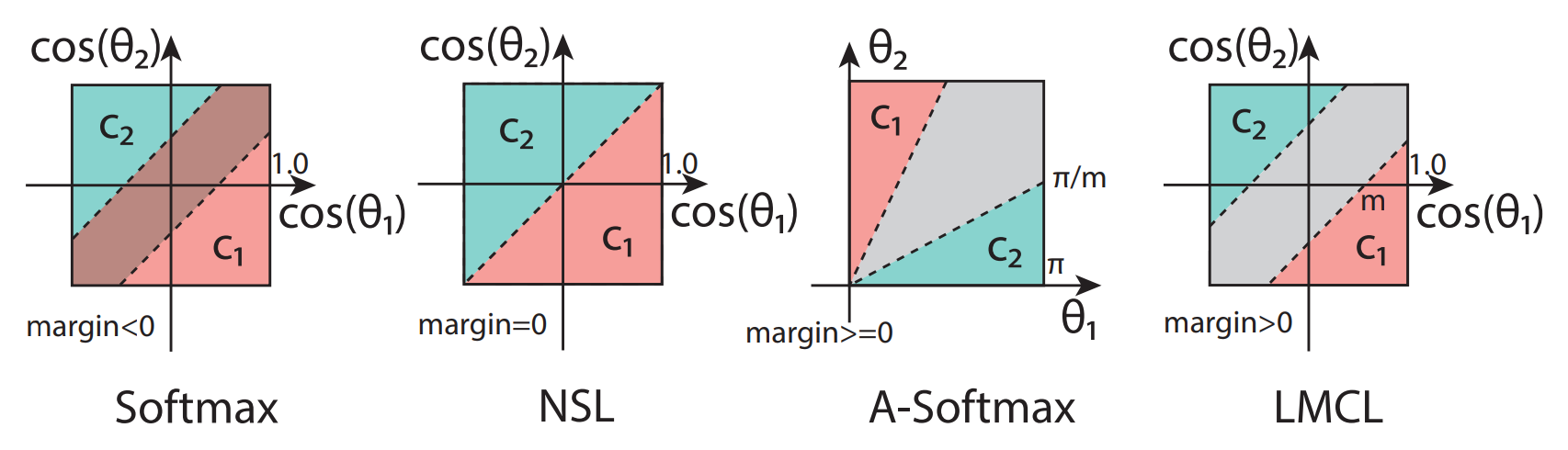
Angular-softmax와 LMCL은 많은 부분이 비슷합니다. 하지만 각 클래스와의 상대적인 각도의 비교를 통해 구분하는 SphereFace와는 달리, CosFace는 정량적인 m의 크기를 정하고 모든 클래스가 m의 차이만큼 벌어지도록 학습합니다. 위의 그래프에서 A-Softmax는 가 0에 가까울수록 margin을 의미하는 회색부분이 작아집니다. 반면에 LMCL은 어는 에서나 일정한 거리의 margin을 유지합니다.
LMCL의 decision boundary는 입니다. Angular-softmax loss와 다르게 클래스 1의 피쳐벡터와 클래스 2의 피쳐벡터의 차이가 m이 되도록 학습합니다.
비교
지금까지 다룬 4개의 Loss에 따른 decision boundary를 정리하자면 다음과 같습니다.
| Softmax | |
| NSL | |
| A-Softmax | |
| LMCL |
A-Softmax에서는 들어온 인풋이미지의 클래스1이 다른 모든 클래스와의 각도 보다 m배 작아지도록 W를 학습합니다. 반면에 LMCL에서는 클래스 간의 각도를 상대적인 값인 m배 축소시키는 방법이 아니라 정량적인 값인 +m 으로 설정하고 학습합니다.
Weights & Feature Vector Normalization
피처벡터는 scale 파라미터 s가 magnitude of radius에 의해 조절되는 구에 분포되어 있습니다. Angular-softmax loss와 LMCL은 이 피처벡터를 normalize하느냐 하지 않느냐에 따라 학습되는 부분이 조금 달라집니다.
A-softmax는 weight vector만 normalize합니다. A-softmax는 피처벡터의 유클리디안 norm과 를 같이 학습합니다. 둘 다 학습한다면, 가 차이가 너무 작은데 비슷한 L2-distance를 갖는 경우에 같은 클러스터로 분류되는 경우가 생길 수도 있습니다.
LMCL은 weight vectors뿐만 아니라 피처벡터 또한 normalize합니다. 둘 다 L2-norm으로 normalize한다면 클래스 분류에는 값만 사용되게 되고 이 각도값의 학습에만 집중하게 합니다. LMCL 논문에서는 다른 변수들이 모두 같은 상황에서 feature vector normalization을 하지 않았을 때보다 feature vector normalization을 했을때 정확도가 1~3% 향상하는 것을 확인했다고 합니다.
실험
![]()
SphereFace와 CosFace 모두 학습과 추론은 일반적인 방법을 따릅니다. metric learning이 적용된 softmax로 CNN 모델을 학습합니다. 추론할 때에는 softmax 부분을 제거하고 CNN 모델에서 추출된 input 이미지의 피쳐벡터로 cosine similarity를 비교해 같은 클래스인지 구분합니다.
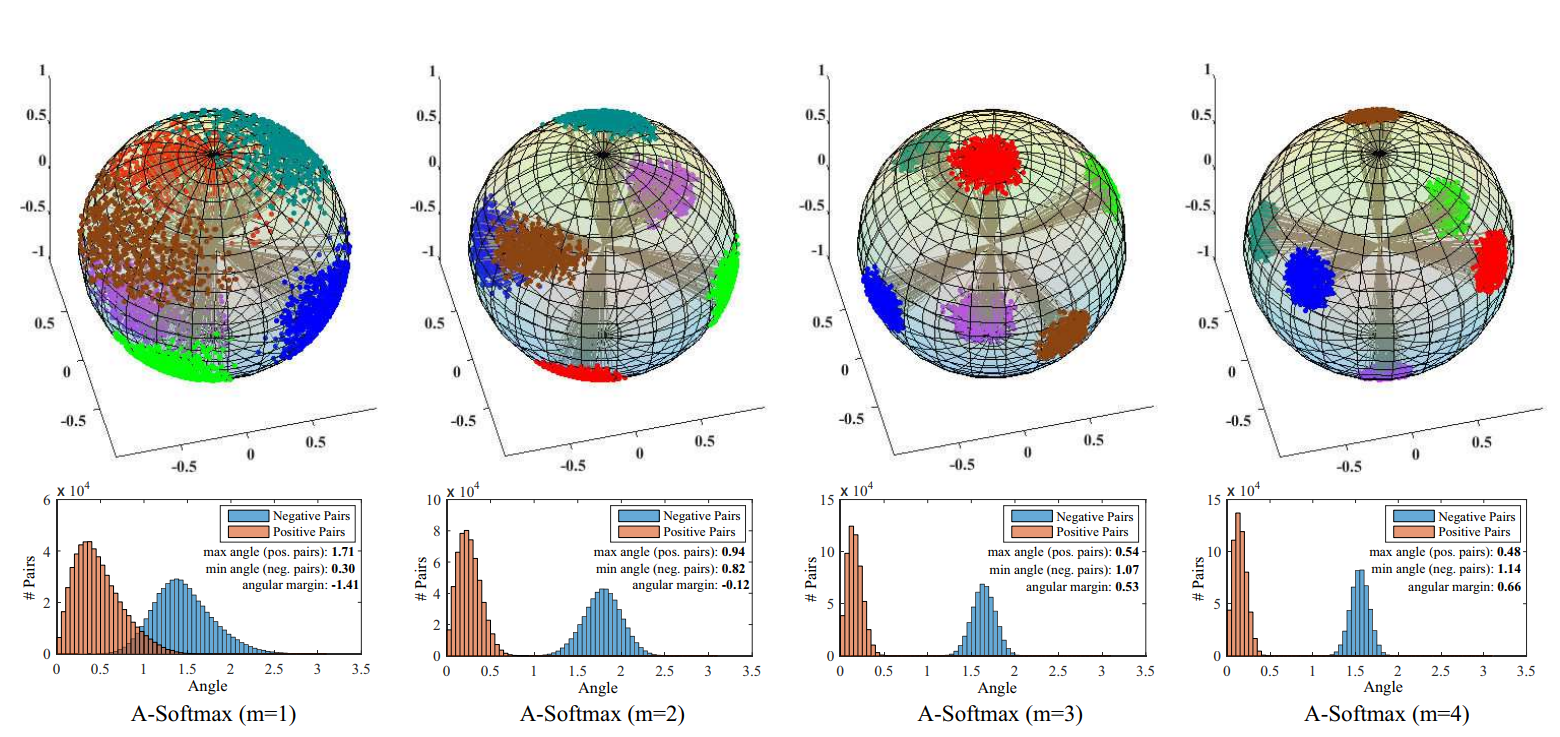
SphereFace에서 m margin이 증가할수록 인풋 이미지 값들이 구에서 더 큰 마진을 가지며 한곳으로 모여들게 됩니다. 따라서 클래스 사이에 분명하게 분리되는 부분을 찾을 수 있게 됩니다. m margin은 intra-class의 angular distance라고 볼 수 있고, m이 커지면 구에 매핑되는 한 클래스 이미지들을 더 좁은 지역으로 매핑하게 됩니다. 논문에서는 m이 4 이상 일때 클래스 구분이 잘 된다고 합니다.
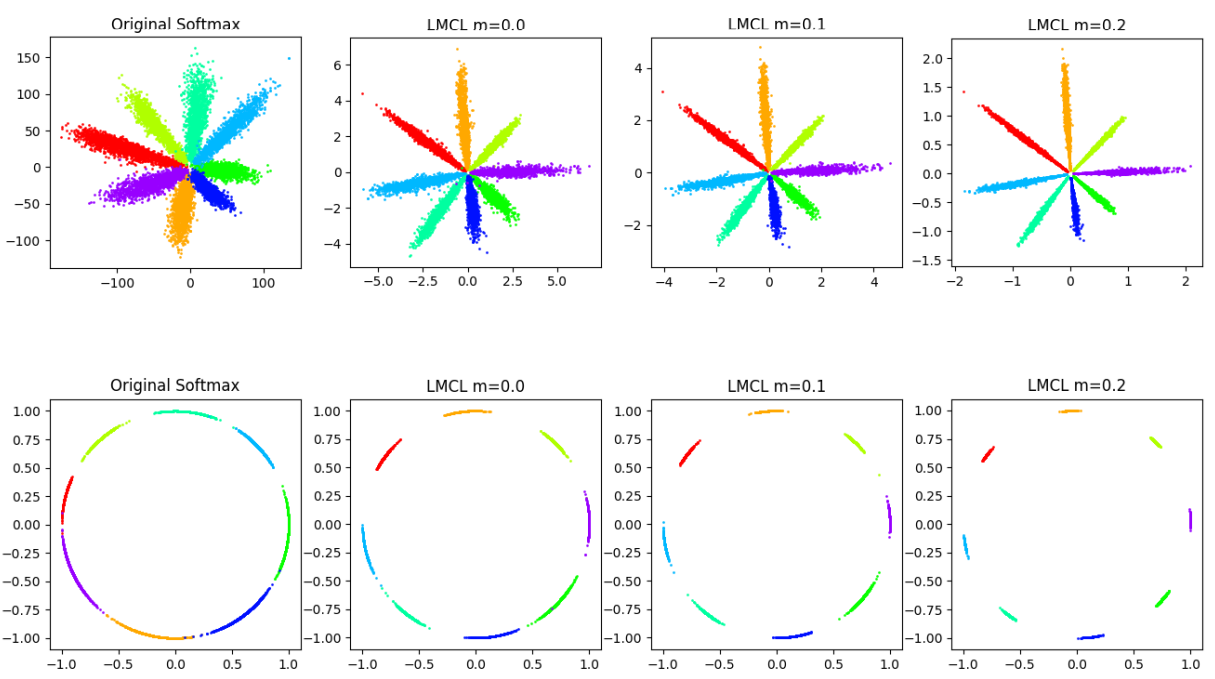
CosFace 논문에서 사용한 데이터셋에서 m이 0.35일때 분류 정확도가 제일 높다고 합니다. 0.35를 넘어가면 오히려 정확도가 떨어지고 0.45를 넘어가면 수렴하지 않는다고 합니다.
결과
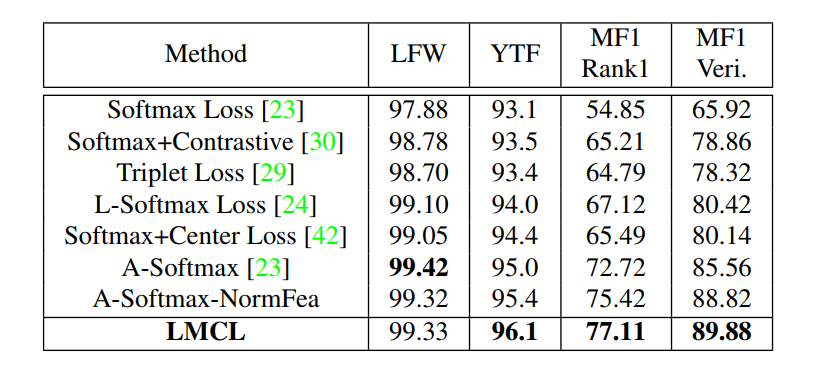
같은 CASIA 훈련 데이터 세트와 같은 64개의 CNN층으로 이루어진 네트워크를 사용해 학습했다고 가정했을 때, 13,233개의 이미지와 5,749개의 클래스를 가진 LFW와 3,425개의 비디오와 1,595의 클래스를 가진 YTF, 그리고 openset를 적용할 106,863개의 이미지와 530개의 클래스를 가진 MegaFace의 Facescrub 데이터셋에서, A-Softmax와 LMCL이 가장 좋은 성능을 보이고 있습니다.
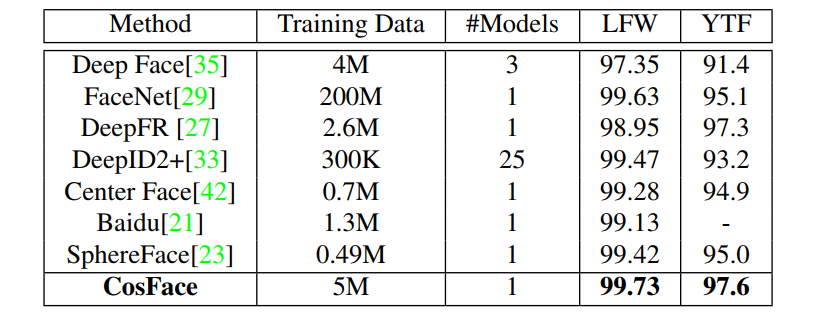
기존에 발표되었던 모델들과 LFW와 YTF에서 verification 정확도를 비교해 보았을 때 SphereFace는 현저히 낮은 데이터 셋(CASIA)으로 학습한 것을 확인 할 수 있다. 성능은 모두 비슷합니다. CosFace는 0.5M개의 이미지 데이터셋인 CASIA-WebFace와 public 및 private 이미지로 구성된 5M개의 데이터 셋으로 훈련하였습니다.
Conclusion
지금까지 다뤄본 Angular-softmax loss와 LMCL의 특징들을 비교해보면 다음과 같습니다.
A-Softmax
- cosine similarity를 softmax에 적용한 거리기반 softmax loss를 처음으로 사용했습니다.
- 같은 클래스가 다른 클래스의 보다 m만큼 작은 각도를 갖도록 학습합니다.
- weight vector만 normalize하고 feature vector와 를 학습합니다.
- 가 작으면 클래스를 구분하는 m또한 작아지게 됩니다.
LMCL
- Angular-softmax loss를 조금 변형한 loss입니다.
- 만약 다른 클래스라면 비슷한 얼굴이라도 정량적인 m 만큼의 거리를 유지하도록 학습합니다.
- 가 작아도 정량적인 m 덕분에 모든 클래스에 대해 일정한 구분이 보장됩니다.
- weight vector뿐만 아니라 feature vector도 normalize하고 만 학습합니다.
정확도 성능면에서 둘 다 비슷한 결과를 보이고 있습니다. 데이터 유형에 따라 그리고 필요에 따라 loss와 normalization을 다르게 적용할 것으로 보여집니다.
#APPENDIX
MegaFace Challenge
MegaFace challenge는 각자의 데이터로 학습한 수 평가하는 challenge 1과, 주어진 4,700,000개 이미지와 672,000개의 클래스로 이루어진 학습데이터로 학습 후 평가하는 challenge2로 나누어 집니다. 유명해진 계기는 challenge 1 때문인데, 1million의 distractor를 이용해 openset을 제공합니다.
모델의 identification 및 verification 성능을 평가하기 위해 Megaface, FaceScrub, FGNet 총 3개의 데이터셋을 각각 필요에 따라 사용합니다.
- 갤러리 데이터셋(distractor)
- MegaFace : 1,000,000개 이상의 이미지
- 프로브 데이터셋
- Facescurb : 100,000개 이상의 이미지
- FGNET : 3500개 이상의 이미지 small은 500,000개 보다 적은 데이터셋, large는 1,000,000개 이상의 데이터셋으로 훈련합니다. FaceScrub은 인터넷에서 끌어온 데이터 셋이라 MS-Select-1M의 있는 celeb의 데이터를 포함합니다. 사람 당 200개의 이미지를 가집니다.
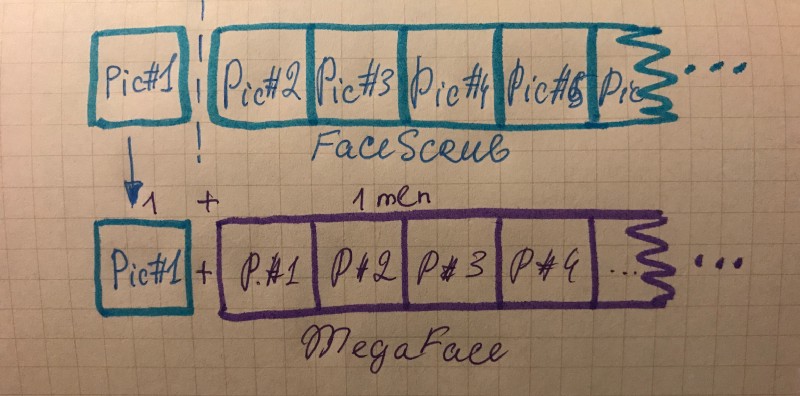
FaceScrub에서 한 클래스를 선택해 pic#n중 pic#1을 뽑아 distractor인 megaface에 더합니다.
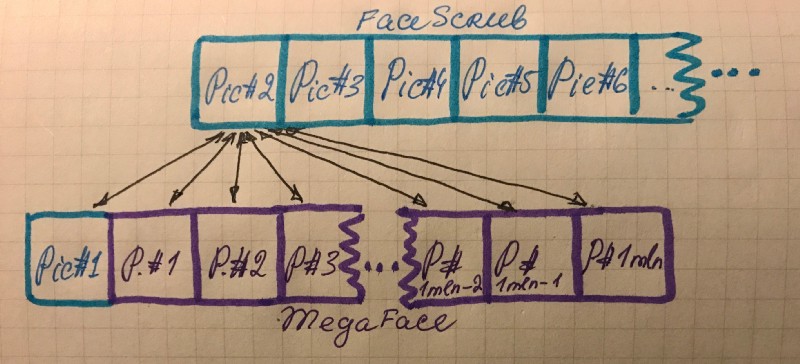
더해진 pic#1와 함께 모든 1mln의 megaface 이미지들의 피처를 뽑아 FaceScrub의 pic#2의 피처와 거리를 비교합니다.
현재는 challenge1의 faceScrub 데이터셋 평가에서 정확도 99%의 더 좋은 성능을 보이는 모델들이 많지만 FGNet은 여전히 FaceNet이 정확도 75%수준으로 상위권에 위치합니다. Challenge2는 faceScrub, FGNet모두 TencentAIlab(CosFace)이 70% 전후의 정확도를 보이며 1위를 하고 있습니다.
Review Face Recognition