Intro
Super Resolution 은 저해상도(Low Resolution) 이미지로부터 고해상도(High Resolution) 이미지를 만들어 내는 연구분야 입니다. 낮은 사양의 촬영기기, 저장소와 전송에 드는 비용을 절약하기 위해 적용되는 손실압축 알고리즘 등에 의해서 낮은 해상도의 이미지가 생성될 수 있으며 이들은 사물을 식별하기 어렵거나 왜곡이 발생하는 등 여러 방면에서 문제가 될 수 있습니다. 이 논문에서는 딥러닝을 이용한 Single Image Super Resolution 연구들에 관해 소개하고 있습니다.
SISR 기술 구분
SISR은 크게 세 종류로 기술이 구분됩니다:
- Interpolation: bicubic interpolation, Lanczos resampling과 같은 것들이 유명한데 이 방법들은 (다른 방법들에 비해)속도가 빠르고 간단하지만 성능이 떨어짐.
- Reconstruction: prior knowledge 기반으로 이미지를 생성함. 시간을 많이 사용하고 scale factor가 많아질 수록(복잡한 이미지일수록?) 성능이 저하된다.
- Learning based: Markov Random Field, Neighbor embedding method, sparse coding method, random forest, Deep Learning based model 등이 제안되었으며 이 논문에서 다루는 것은 DL 기반 방법.
State-of-the-Art Deep SISR Networks
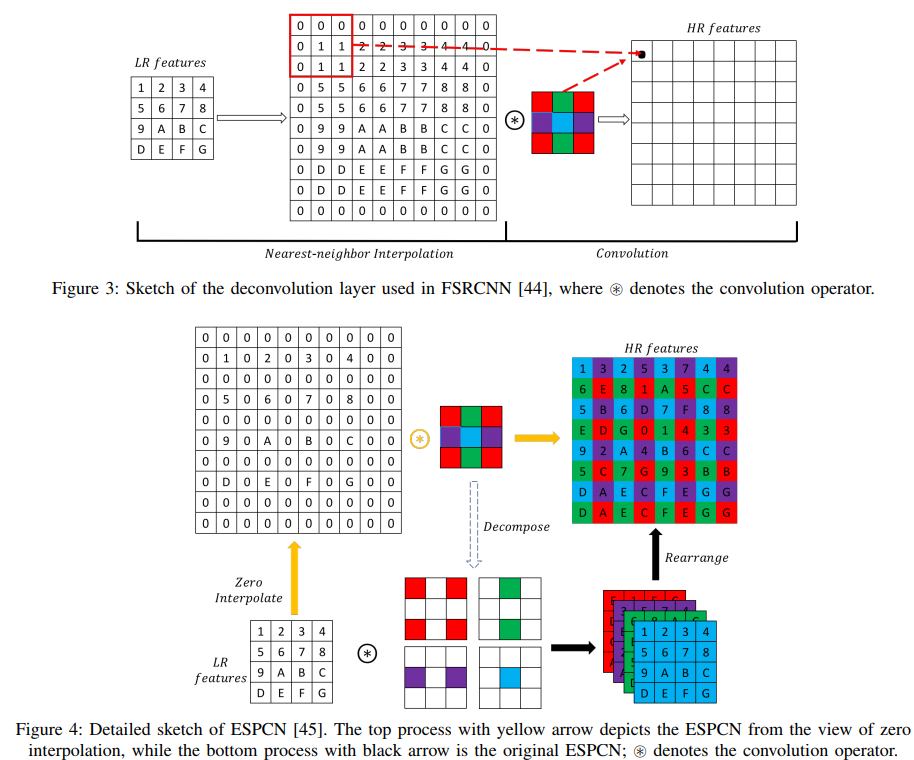
컨볼루션 신경망을 기반으로 제안된 SISR 초기 네트워크들인 FSRCNN, ESPCN의 구조이며 이 방법들은 CNN과 interpolation 방법을 조합해서 고해상도 이미지(HR feature)를 얻어내고 있습니다. FSRCNN은 저해상도 이미지(LR feature)에 Nearest-neighbor Interpolation을 적용, 크기를 4배로 (4x4 -> 8x8 + zero padding) 늘린 다음 CNN 레이어에 통과시키는 방법을 사용하고 있으며 ESPCN에서는 CNN 레이어를 decompose 해서 4개의 필터로 분해한 다음 LR feature 를 통과시켜 4개의 결과를 얻어내고 이를 병합하는 방법(까만 화살표)을 적용하고 있습니다. 이를 Zero Interpolation 방법으로 보면 노란색 화살표처럼 동작하게 됩니다.
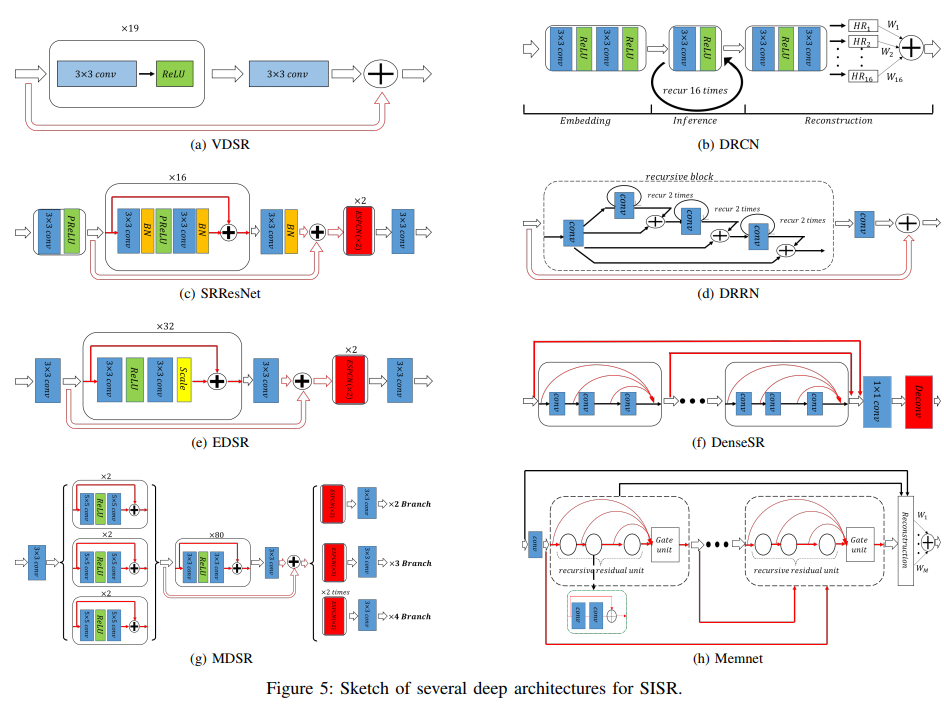
위 그림은 SISR에서 분야에서 제안된 주요 Deep Architecture 입니다. 각각의 네트워크는 다음과 같은 특징을 가지고 있습니다:
- VDSR: VGG-20 을 사용한 모델. 이미지를 bicubic interpolation으로 사이즈를 키운 다음 네트워크에 통과시키는 방식.
- DRCN: VDSR처럼 20레이어를 쓰지만, 같은 convolution 레이어를 16번 통과시키는 방식을 제안해서 학습시켜야 할 레이어가 5개로 줄어들었다. 그리고 multi-supervised strategy를 제안하는데 이는 16번 반복되는 conv 레이어의 중간 결과들을 합쳐서 최종 결과로 사용하는 방법.
- SRResNet: ResNet 구조(Residual Block)를 SR에 사용함. 성능이 잘 나온다고 합니다.
- DRRN: SRResNet 에서 residual block에 recursive(DRCN에서 제안한) 구조를 적용한 것.
- EDSR: 1) SRResNet에서 적용했던 Batch Normalize를 제거함(BN은 classification을 위해서 디자인된 것이므로 세부 표현력이 중요한 SRdp 적합하지 않다고 주장하고 있음). 2) layer 자체의 output 크기를 늘리는 scale 과정이 추가됨. 3) 3x, 4x 네트워크를 구성할 때 2x로 학습된 네트워크를 가지고 시작하면(pre-train) 성능이 더 좋아질 수 있다는 점을 제안.
- MDSR: EDSR 에서 multi-scale output을 동시에 만들 수 있는 네트워크 제안. 학습 도중에는 2x, 3x, 4x 브랜치 중에서 하나가 임의로 선택되어서 레이어들을 업데이트한다.
- DenseSR: DenseNet 기반의 구조. 모든 convolution layer의 output이 block 끝에서 합쳐져서 사용됨.
- Memnet: DenseSR 기반. recursive와 residual block. dense connection, short-term memory와 longterm memory 개념도 들어간 네트워크.
SISR 네트워크에서 독특한 제안점들은 중간 레이어의 출력을 맨 뒤로 보내는 것과 같은 Convolution 레이어를 여러 번 통과한다는 점 입니다. DRCN에서 제안된 방법은 학습시켜야 하는 레이어 수를 줄이고 결과 이미지를 더 선명하게 만드는 효과가 있다고 합니다.
깊게 레이어를 쌓아나가면서 이미지 전체의 featrue를 볼 수 있게하는 기존 네트워크들과 달리, Super Resolution에서는 픽셀마다 세밀한 표현을 할 수 있도록 훈련되어야 하기 때문에 네트워크의 앞부분 레이어 정보를 뒤로 보내는 것이 좋은 효과를 보이는 것 같습니다.
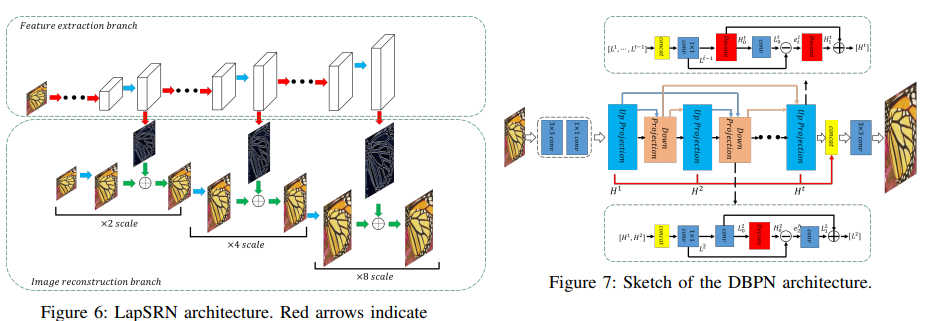
그 외에 소개된 또 다른 방법으로는 Laplacian Pyramid 구조를 가지는 LapSRN, Up/Down projection 구조를 가지고 있는 DBPN 네트워크가 있으며 Generative model 기반 SISR 네트워크인 PixelCNN도 소개하고 있습니다. PixelCNN은 autoregressive 계열의 generative model이며, convolution 레이어 파라미터의 일부를 0으로 설정해서 선명한 이미지를 얻는 방법ㅇ르 제안하고 있습니다.
성능 비교
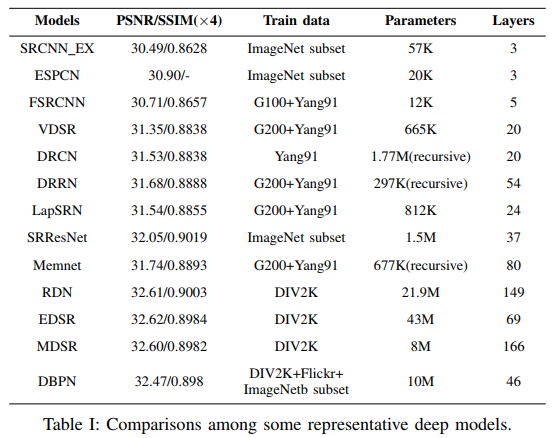
위에서 언급한 네트워크들의 성능 비교입니다. 성능비교 지표로는 PSNR(Peak Signal-to-Noise Ratio), SSIM(Structural Similarity)를 사용하고 있습니다. 아래는 3개의 방법(bicubic, SRResNet, SRGAN)을 이용해서 SISR을 적용한 결과를 비교하고 있습니다. 실험 결과에서는 SRResNet이 가장 좋은 성능을 보이며 SRGAN 역시 선명한 복원 결과를 보여주고 있습니다.

실험 결과에서 눈으로 보기에는 SRGAN이 더 선명한 이미지를 보여주는 것 같지만 옷이나 모자와 같은 세밀한 부분에서 GAN모델은 구체적인 무늬를 만들려고 시도하면서 고해상도 이미지에는 없는 것을 만들다 보니 측정 수치가 더 낮게 나오는 것 같습니다.
Conclusion
이 논문에서는 딥러닝을 이용한 Super Resolution 영역의 연구들을 소개하고 있습니다. 고해상도의 이미지는 물체를 인식하는 이미지 처리 분야에서 더 정확한 인식을 가능하게 만들 수 있지만 다양한 이유로인해 실제 문제에서는 저해상도 이미지가 주어질 수 있습니다. Super Resolution 연구는 이같은 문제를 해결할 수 있는 흥미로운 분야라고 생각됩니다.
Super Resolution survey