Learning Transferable Architectures for Scalable Image Recognition
Written by Hyunsuk Yoo
이번 포스팅은 다음 논문들의 내용을 이용하여 정리하였습니다.
요약
- 소개해드릴 논문은 CVPR 2018년에 발표된 논문입니다.
- 본 논문에서는 작은 dataset의 search space에서 성능이 좋은 model architecture를 찾은 뒤, 해당 architecture를 더 큰 dataset에서 적용한 결과를 소개하고 있습니다.
- 저자들이 제안하는 “NASNet architecture”는 CIFAR-10 dataset에서 탐색으로 찾은 cell을 stacking하여 ImageNet dataset에도 적용한 convolutional architecture 입니다. NASNet은 ImageNet datset에서 state-of-the-art accuracy를 보이면서, FLOPS는 현저하게 낮았습니다.
- Image classification task를 통해 학습된 image feature들을 object detection에도 적용하여, COCO dataset에서 state-of-the-art 보다도 4.0% 높은 mAP를 얻었습니다.
Introduction
- 최근에 Neural Architecture Search with Reinforcement Learning에서 제안된 Neural Architecture Search (NAS) framework는 reinforcement learning search method를 이용하여 architecture configuration을 optimize 시키는 방법입니다. 하지만 NAS를 큰 dataset에 적용하면 computational cost가 매우 크다는 단점이 있습니다.
- 본 논문은 이러한 단점을 극복하기 위해서 ImageNet보다 훨씬 작은 dataset인 CIFAR-10 dataset에서 architecture 탐색을 시행하였고, search space의 network를 동일한 구조의 convolutional structure(“cell”)로 한정하였습니다.
Method
- 논문에서 사용하는 architecture 탐색 방법은 Neural Architecture Search (NAS) framework입니다. NAS에서는 controller RNN이 다양한 architecture를 갖는 child network를 sampling하고, 각 child network가 validation set에서 보이는 accuracy를 이용하여 controller weight를 update 합니다.
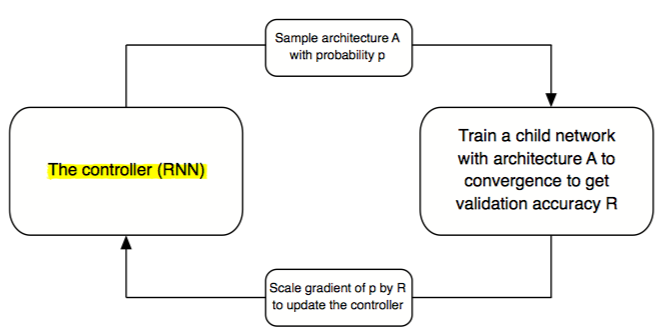
- Controller RNN을 이용해서 CNN architecture에서 흔히 발견되는 motif들 (convolutional filter banks, nonlinearities, connections, etc.)로 표현되는 generic convolutional cell을 예측하고, 그러한 cell들을 stack시키면 어떠한 spatial dimension과 filter depth도 처리할 수 있는 scalable architecture를 만들 수 있게 됩니다.
- 이러한 scalable architecture를 만들기 위해서는 두가지 종류의 convolutional cell이 필요하고, 두 종류의 cell은 모두 다른 architecture를 갖게 됩니다.
- Normal cell: normal cell은 같은 dimension의 feature map을 return하게 됩니다.
- Reduction cell: reduction cell은 height과 width의 크기가 반으로 줄어 든 feature map을 return하게 됩니다.
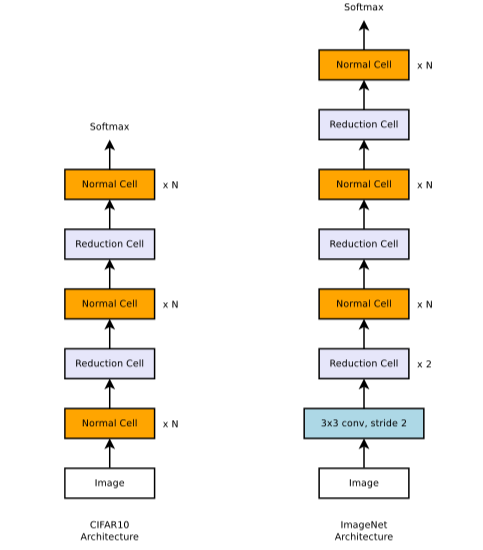
- 참고로 CIFAR-10에 비해 ImageNet에서의 architectures는 reduction cell의 갯수가 많은데, 그 이유는 image size가 각각 299x299와 32x32이기 때문입니다.
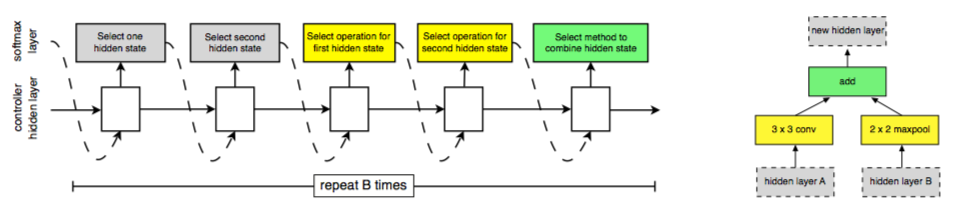
- Controller RNN은 convolutional cell의 structure를 recursive하게 예측하게 됩니다.
- Step 1. 전 lower layer의 output을 hidden state으로 선택합니다.
- Step 2. Step 1과 같은 과정으로 다른 hidden state을 선택합니다.
- Step 3. Step 1에 적용할 operation을 선택합니다.
- Step 4. Step 2에 적용할 operation을 선택합니다.
- Step 5. Step 3과 Step 4를 합칠 수 있는 method를 선택합니다.
- Controller RNN은 step 1~step 5의 과정을 총 B번 (논문에서 B=5) 반복하게 되고, 이는 cell의 B block에 해당합니다.
Results
- Controller RNN의 architecture search 과정은 NVIDIA P100 GPU 500대를 이용하여 총 2000GPU-hour가 걸렸습니다. 이는 기존의 search 방법에 비해 약 7배 정도 빠른 work time 입니다.
- 참고로 reinforcement learning을 이용했을 때 찾은 architecture는 random search를 이용해서 찾은 구조보다 CIFAR-10에서 성능이 약 1% 정도 좋은 것으로 나왔습니다.
- 가장 성능이 좋았던 normal cell과 reduction cell의 구조는 다음과 같았습니다.
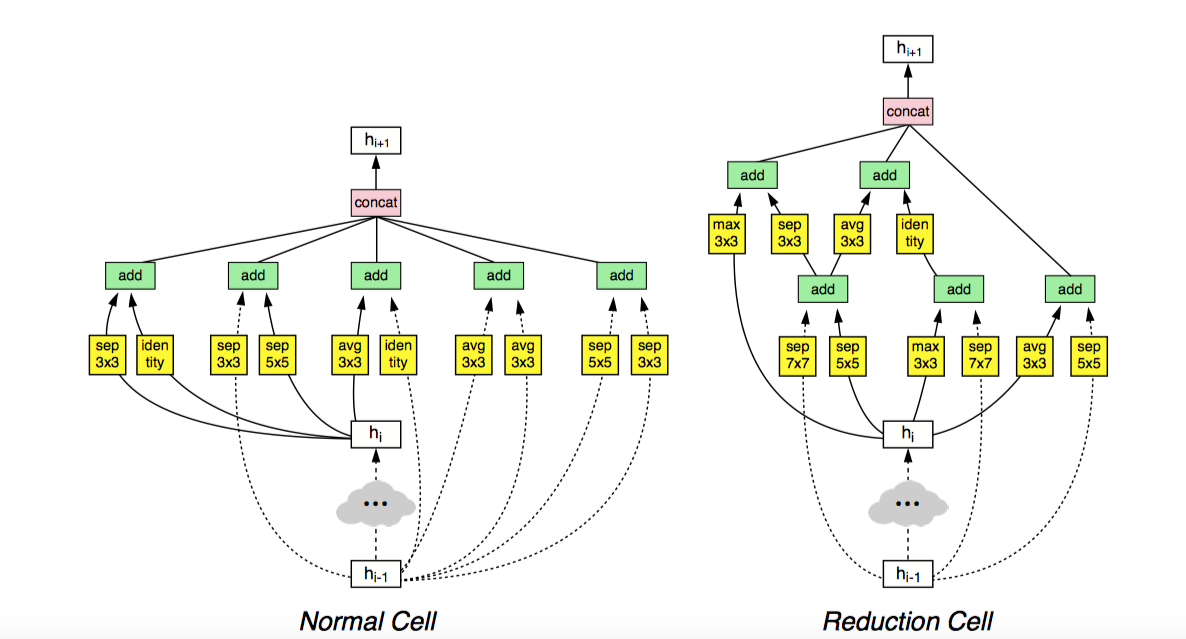
- 가장 성능이 좋았던 NASNet-A (6 @ 4032)을 이용하면, CIFAR-10에서는 2.4% error rate을 보였고, ImageNet에서는 각각 82.7% top-1, 96.2% top-5 accuracy를 보였습니다.
- NASNet-A(6 @ 4032)의 compact한 version인 NASNet-A(4 @ 1056)을 이용하면 parameter 갯수는 5.3M밖에 안되지만, ImageNet에서 74.0% top-1, 91.% top-5 accuracy를 보입니다. 이는 4.2M의 parameter를 사용해서 70.6% top-1 89.5% top-5 accuracy를 보이는 MobileNet 보다 훨씬 좋은 결과이고, mobile platform에 NASNet을 사용할 수 있다는 것을 시사합니다.
- NASNet-A architecture를 backbone으로 이용하여 Faster-RCNN object detection을 실행했을 때, test set에서 mAP가 43.1%가 나왔습니다. 이는 state-of-the-art detection network 이상의 성능입니다. 각각 Inception-ResNet-v2와 NASNet-A를 backbone network로 이용해서 Faster-RCNN을 시행한 결과는 다음과 같습니다.
