Learning Deep Features for Discriminative Localization
Written by Hyunsuk Yoo
이번 포스팅은 다음 논문들의 내용을 이용하여 정리하였습니다.
- Learning Deep Features for Discriminative Localization
- Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
요약
- 소개해드릴 논문은 CVPR 2016에 발표된 논문입니다.
- 본 논문에서는 global average pooling (GAP) layer를 이용하여 class activation mapping (CAM)을 구현하였습니다. 제시된 방법을 이용하면 bounding box에 대한 label이 없이도 classification network를 이용하여 semi-supervised learning을 통해서 object localization을 할 수 있습니다.
- Grad-CAM과의 차이는 CAM 구현을 위해서 network 구조의 변형이 필요하다는 점입니다. Activation map을 구하기 위해서 마지막 convolutional layer 이후의 fully connected layer들을 모두 제거하고 global pooling layer로 대체해야 하고, pooling layer를 softmax layer와 직접 연결을 해야 합니다.
Introduction
- Object location을 explicit하게 제시하지 않더라도, classification을 위해서 CNN은 implicit하게 object detection을 학습하게 됩니다. 하지만 마지막 단계에서 classification을 하기 위해 fully-connected layer를 이용하게 되면, 이러한 localization information은 소실되게 됩니다. 따라서 network의 구조를 변형시키면 classification에 필요한 정보 뿐만 아니라 localization information도 유지하는 것이 가능할 것입니다.
- 기존에 class-specific image region을 뽑기 위한 방법으로는 특정 image region을 masking하는 방법, multiple-instance learning 등의 방법이 사용되었습니다. 이러한 방법들은 end-to-end training이 불가능하고, CAM을 구하기 위해서는 forward pass를 여러 번 해야 하는 단점이 있습니다.
Methods
- 논문에서 제시한 model의 구조는 아래 그림과 같습니다.
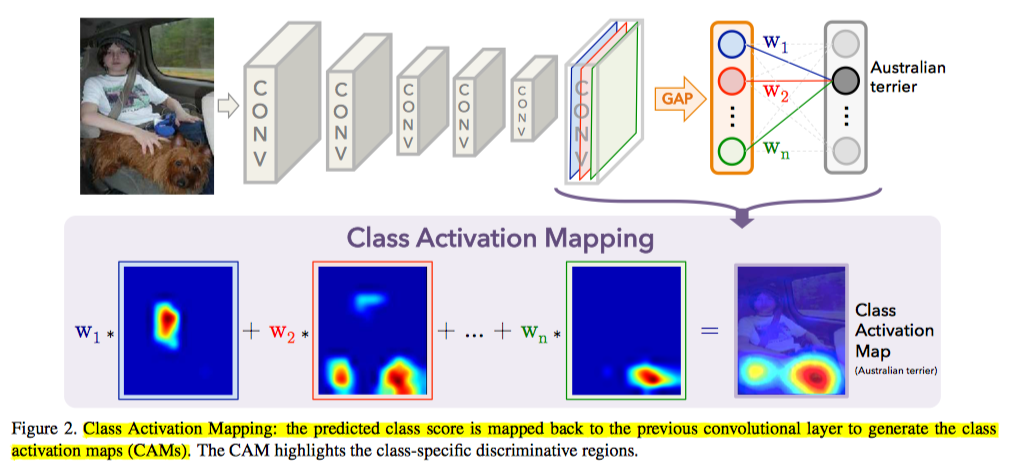
- Model의 구조를 보면 마지막 fully-connected layers들을 제거하고 GAP + softmax layer로 대체한 것을 알 수 있습니다. 이러한 구조를 사용했을 때 parameter 숫자는 현저하게 감소하게 됩니다 (e.g. VGG-net에 대해 90% less parameter).
- GAP 전의 마지막 convolutional layer의 spatial resolution이 좋을수록 localization 능력이 향상되므로, 네트워크들에 대해 3x3, stride 1, pad 1, 1024 unit의 convolutional layer를 추가하였습니다.
- 마지막 conv layer은 GAP layer와 연결되어 있습니다. Global max pooling이 아닌 global average pooling layer 를 사용한 이유는 object의 extent를 identify하는데 global max pooling보다 더 효과적이기 때문입니다. GAP layer는 마지막 conv layer의 spatial average를 output으로 내고, 그 값들에 대한 spatial average를 구해 CAM을 얻는다고 생각하시면 됩니다. 수학적으로 각 class 에 대한 class activation map 는 다음과 같이 표현할 수 있습니다.
따라서 가 last convolutional layer의 activation이라 할 때, 각 class score 는
입니다. - 논문에서 제시한 model을 이용해서 CAM을 구한 결과들은 다음과 같습니다.

Results
- Classification
- Network의 구조를 변형시켰기 때문에, classification performance는 1-2% 정도 저하됩니다. 이러한 network 구조 변형으로 가장 영향을 많이 받는 network는 AlexNet을 기반으로 한 네트워크입니다.
- Localization
- Classification 성능이 좋은 네트워크가 localization 능력도 좋은 것으로 확인되었습니다.
- CAM으로부터 bounding box를 얻기 위해, thresholding technique를 이용하여 heatmap을 segmentation 하였습니다. CAM의 max value와 비교했을 때 20% 이상인 region을 segmentation 하였고, segmentation된 영역을 포함하는 최대 크기의 box를 bounding box로 설정하였습니다. 이 과정을 classifiation output 중 가장 확률이 높은 5개의 class에 대해 진행하였습니다.
- 제시된 localization 방법은 explicitly labeled된 bounding box를 사용하지 않은 weakly supervised learning 방법이지만, ILSVRC test set에 대해 GoogLeNet-GAP의 top-5 localization error가 37.1% 밖에 되지 않았습니다.
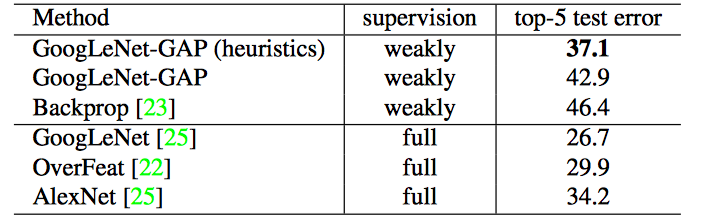
- 그 이외의 결과들
- GAP output에 linear SVM을 연결시켜서 학습시켰을 때, 네트워크가 generic discriminative localization을 효과적으로 하는 것이 확인되었습니다. 이러한 generic localizble feature를 이용하여 recognition task, pattern discovery, concept localization도 효과적으로 수행하였습니다.
개인적으로 생각하는 논문의 장단점
- 장점:
- Semi-supervised learning을 이용하여 classification network만으로 single pass에 classification 및 localization을 수행하였습니다.
- CAM의 성능이 매우 좋습니다. 참고로 ChexNeXt에서도 heat map을 얻기 위해 본 논문에서 제시한 방법을 사용하였고, 매우 정확한 heat map이 얻어졌습니다.
- 단점:
- 인위적으로 network architecture를 변형시켜야 되고, fully connected layer를 사용할 수 없습니다.
- Localization이 가능하지만, state-of-the art localization network와 비교해서 성능이 낮습니다.