End-to-end task TODS is challenging since knowledge bases are usually large, dynamic hard to incorporate into a learning framework. We propose the global-to-local memory pointer (GLMP) networks to address this issue. [Paper]
1. Introduction
- Three main components
- Global memory encoder
- Local memory decoder
- Shared external knowledge
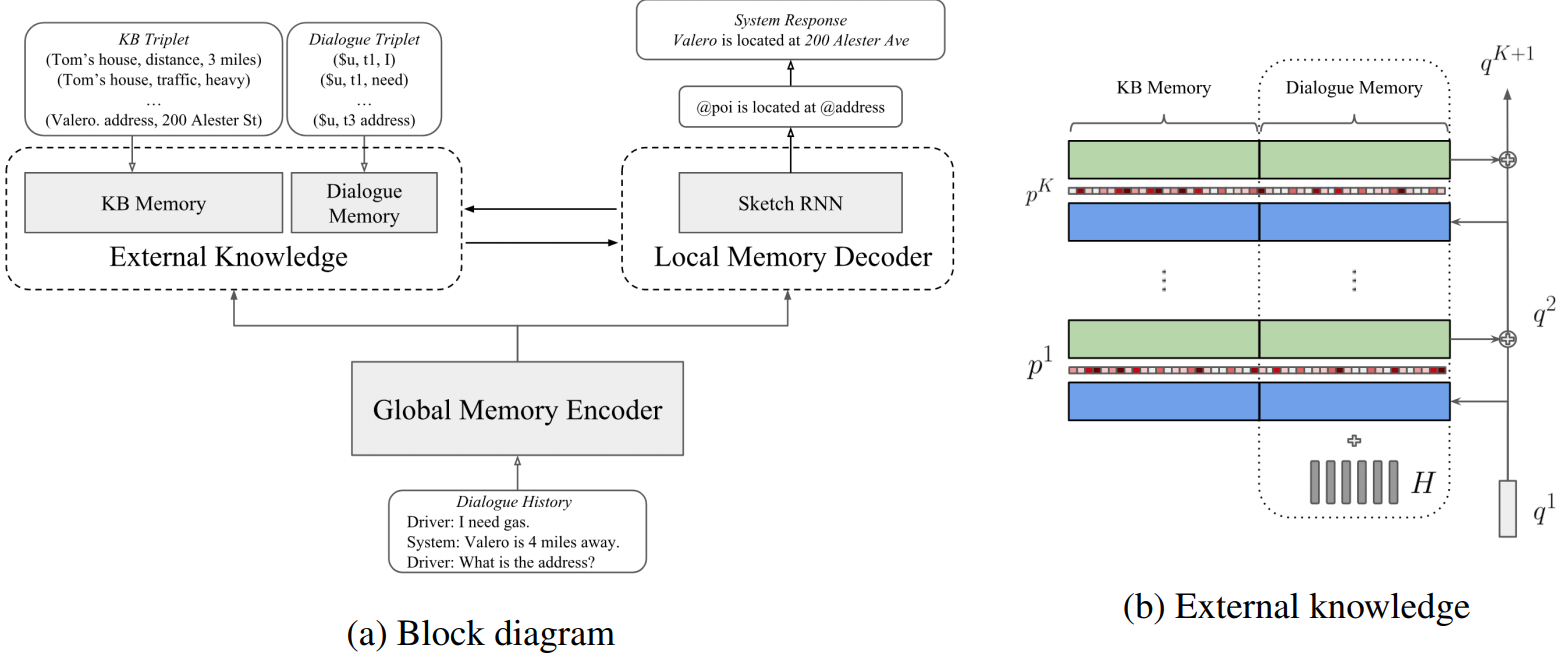 Figure1. The proposed (a) global-to-local memory pointer networks for task-oriented dialogue
systems and the (b) external knowledge architecture
Figure1. The proposed (a) global-to-local memory pointer networks for task-oriented dialogue
systems and the (b) external knowledge architecture
- Global memory pointer modifies the external knowledge
- The local memory decoder first uses a sketch RNN to obtain sketch responses without slot values
- The decoder generates local memory pointer to copy words from external knowledge and instantiate sketch tags
2. GLMP Model
- Dialogue history
- Knowledge base (KB) information
- System response
- Model Outline
- The global memory uses a context RNN to encode dialogue history.
- Then, the last hidden state is used to read the external knowledge and generate the global memory pointer
- During the decoding stage, the local memory decoder first generates sketch responses by a sketch RNN.
- Then the global memory pointer and the sketch RNN hidden state are passed to the external knowledge as a filter and a query
- The local memory pointer can copy text from the external knowledge to replace the sketch RNN tags and obtain the final system response
2.1 External Knowledge
Two functions — global contextual representation and Knowledge read & write
Global Contextual Representation
External Knowledge contains global contextual representation that is shared with the encoder and the decoder.
End-to-end memory networks are to store word-level information for KB memory and Dialogue memory
-
KB memory
Each element in B is represented in the triplet form as (Subject, Relation, Object)
-
Dialogue memory
The dialogue context X is stored in the dialogue memory module, as a triplet form
 Table1. An in-car assistant example on the navigation domain. The left part is the KB information and the right part is the conversation between a driver and our system
Table1. An in-car assistant example on the navigation domain. The left part is the KB information and the right part is the conversation between a driver and our system
Triplet KB : {(Tom’s house, distance, 3 miles) , .. , (Starbucks, address, 792 Bedoin St)}
Triplet Dialogue : {($user, turn1, I) , (user, turn1, need), (user, turn1, gas) … )}
- For the two memory modules, a bag-of-word representation is used as the memory embedding
- During inference, we copy the object word
- For example, 3 miles will be copied to (Tom’s house, distance, 3 miles) is selected
- Here Object( . ) denotes the function as getting the object word from a triplet
Knowledge read & write
- External knowledge is composed of a set of trainable embedding matrices
- Denote memory in the external knowledge as
-
To read the memory, the external knowledge needs an initial query vector q_1
-
It can loop over K hops and computes the attention weights at each hop k using
-
Note that the attention weight, p, is a soft memory attention that decides the memory relevance w.r.t the query vector
-
-
Then the model reads out the memory o by the weighted sum over c and update the query vector q
2.2 Global Memory Pointer
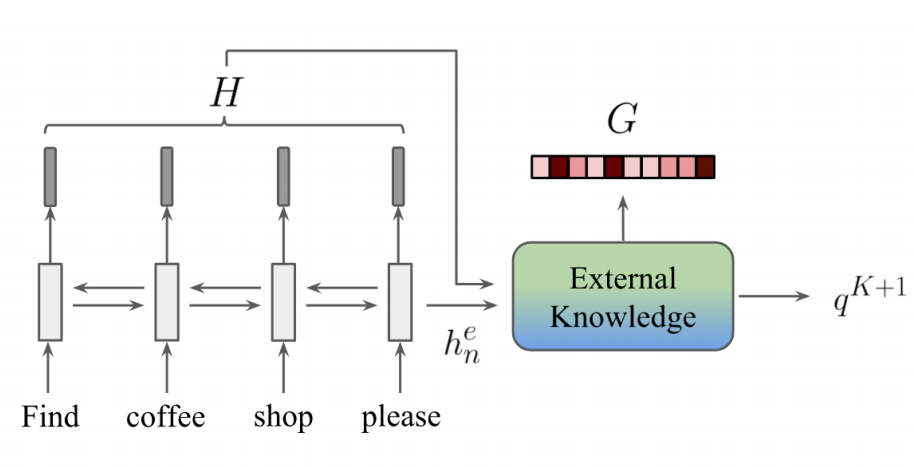 Figure2. Global memory encoder
Figure2. Global memory encoder
- Context RNN is used to model the sequential dependency and encoder the context X
- End-to-end MN cannot reflect the dependencies between memories (*)
- The hidden states are written into the external knowledge as shown in Figure 2
- This can solve the above problem (*)
- The last encoder hidden state serves as the query to read the external knowledge and get two outputs — (a) global memory pointer and (b) memory readout
Context RNN
- GRU is used to encode the dialogue history into the hidden states
-
The last hidden state h_n is used to query the external knowledge as the encoded the dialogue history
-
The hidden states h is added to the original memory representation
Global Memory Pointer
- Global memory pointer is a vector containing real values between 0 and 1.
-
Unlike conventional attention mechanism that all the weights sum to one, each element in G is an independent probability.
-
Query the external knowledge using h_n until the last hop
-
take an inner product
-
followed by the Sigmoid function
-
-
To further strengthen the global pointing ability, we add an auxiliary loss to train the global memory pointer as a multi-label classification task
- 1 if the object words in the memory exits in the expected system response Y
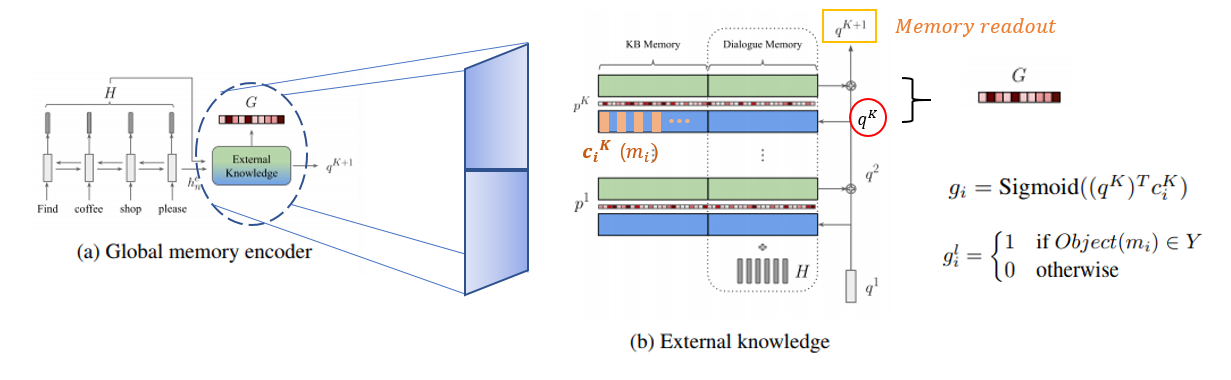
Figure 3. The process of modelling the loss function
- Then the global memory pointer is trained using binary cross-entropy loss Loss_g between G and G^label
Loss Function
- Lastly, the memory readout, q^K+1 is used as the encoded KB information
2.3 Local Memory Decoder
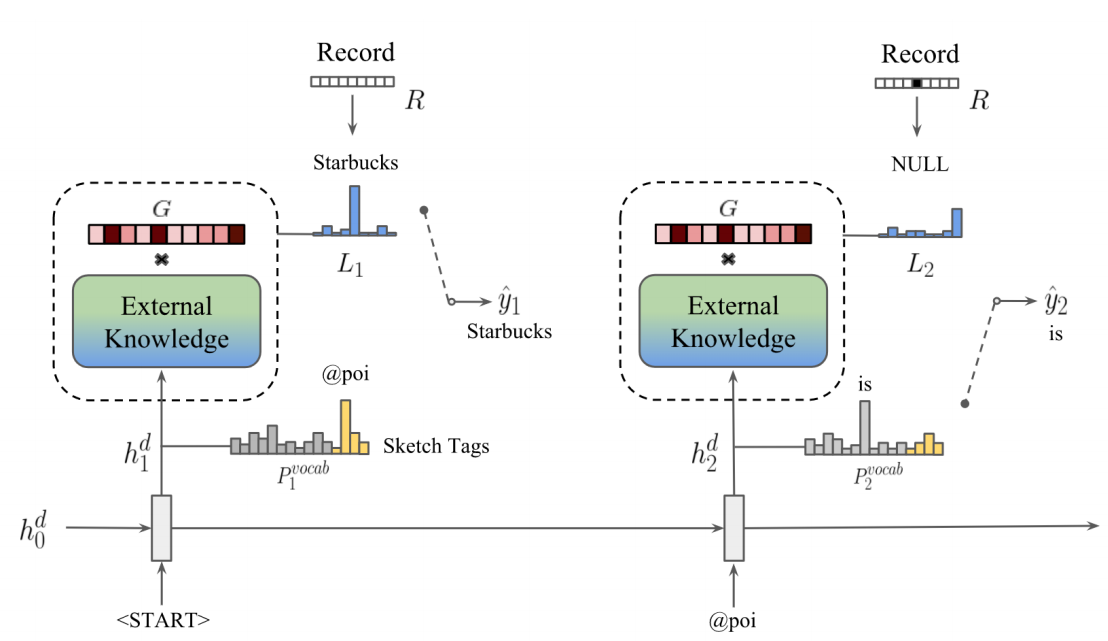 Figure 4. Local memory decoder
Figure 4. Local memory decoder
- From the Global memory encoder, we found
- Local memory decoder —> initializes its sketch RNN using the concatenation of the h_n and q^K+1
- This generates a sketch response with the sketch tags but without slot values
- Eg. sketch RNN would generate “@poi is @distance away “ instead of “Starbucks is 1 mile away”
- At each decoidng time step, the hidden state of the sketch RNN is used for two purposes:
(a) Predict the next token in vocabulary , which is same as standard Sequence-to-Sequence (S2S)
(b) Serve as a vector to query the external knowledge
- If a sketch tag is generated, G is passed to the external knowledge and the expected output word will be picked up from the local memory pointer
- Otherwise the output word is the word that generated by the sketch RNN (S2S)
Sketch RNN
Use GRU to generate a sketech reponse Y, without real slot values
- Sketch RNN learns to generate action template based on encoded dialogue histroy and KB information
- At each decoding time step, the sketch RNN hidden state (h_d) and its output distribution (P_vocab) are defined :
- Use standard cross-entropy loss to train the sketch RNN
- We replace the slot values in Y into sketch tags based on the provided entity table.
- The sketch tags (ST) are all possible slot types that start with a special token, for exampel, @address stands for all the address information
Local Memory Pointer
Local memory pointer contains a sequence of pointers,
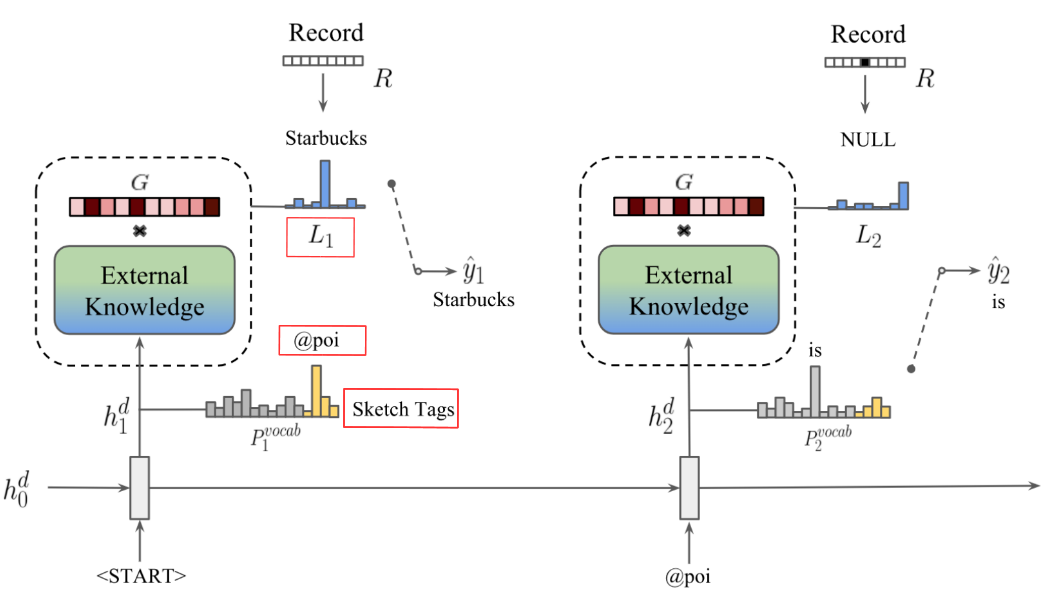 Figure 5. Local memory decoder
Figure 5. Local memory decoder
- At each time step t, the global memory pointer G modifies the global contextual representation using its attnetion weights
- And then the sketch RNN hidden state h_d queires the external knowledge.
- The memory attention in the last hop is the corresponding local memory pointer L_t which is represneted as the memory distribution at time step t
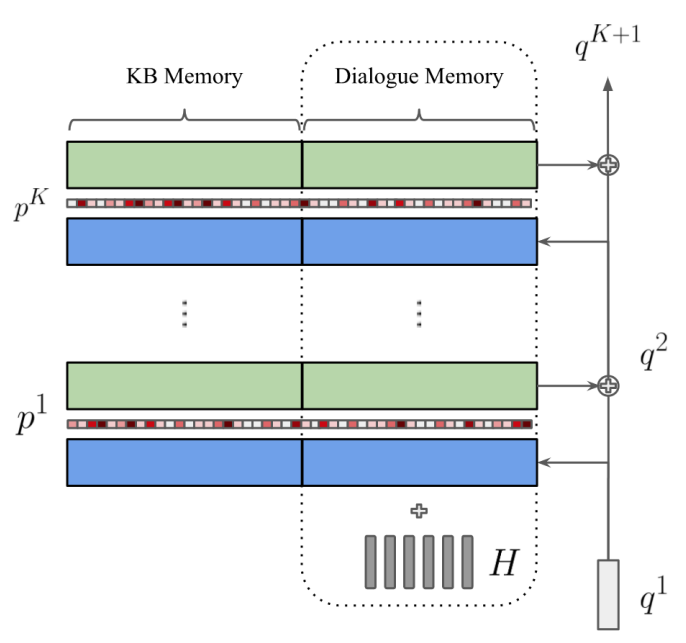
Figure 6. The representation of “local memory pointer as the memory attention in the last hop (Here, p^K is L^t)
- To train the local memory pointer, a supervision on top of the last hop memory attention in the external knowledge is added.
- We first define the position label of local memory pointer L_label at the decoding time step t as
- The position n+l+1 is a null token in the memory that allows us to calculate loss function even if y_t does not exist in the external knowledge.
- Then, the loss between L and L_label is defined as
- Furthermore, a record R ∈ R^(n+l) is utilized to prevent from copying same entities multiple times.
- All the elements in R are initialized as 1 in the beginning.
- During the decoding stage, if a memory position has been pointed to, its corresponding position in R will be masked out. (i.e R_i is set to be zero)
- During the inference time, yˆt is defined as
- Lastly, all the parameters are jointly trained by minimizing the weighted-sum of three losses (α, β, γ are hyper-parameters)
3 Experiments
Datasets
- bABI dialogue (Bordes & Watson, 2017)
-
Includes 5 simulated tasks in the restaurant domain
-
Task 1-4 are about
- calling API calls
- modifying API calls
- recommeding options
- providing additional information
-
- Task 5 is the union of Tasks 1-4
-
Two test sets for each task — one follows the same distribution as the training set and the other has OOV entity values
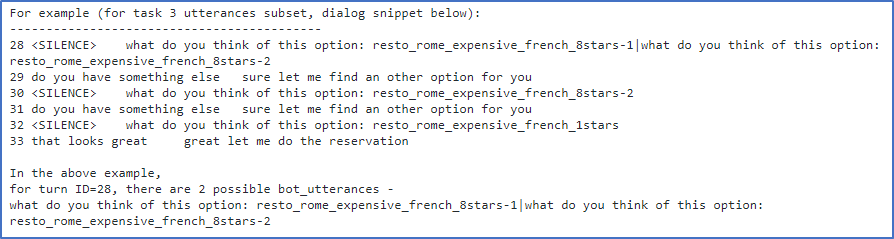
Table 2. Example of Task 3 from bABI dialogue dataset (https://github.com/IBM/permuted-bAbI-dialog-tasks)
-
Stanford multi-domain dialogue (SMD)
-
Human-Human and multi-domain doalogue dataset
-
Three distinct domains
- Calendar scheduling
- Weather information retrieval
- Point-of-interest navigation
-
Results
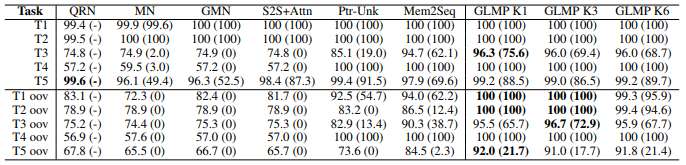 Table 3. The result of bABI dataset
Table 3. The result of bABI dataset
Per-response accuracy and completion rate (in the parentheses) on bAbI dialogues. GLMP achieves the least out-of-vocabulary performance drop. Baselines are reported from Query Reduction Network (Seo et al., 2017), End-to-end Memory Network (Bordes & Weston, 2017), Gated Memory Network (Liu & Perez, 2017), Point to Unknown Word (Gulcehre et al., 2016), and Memory-to-Sequence (Madotto et al., 2018)
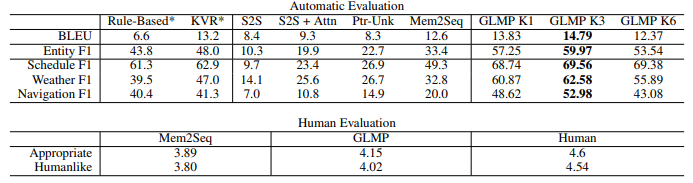 Table 4. The result of SMD dataset
Table 4. The result of SMD dataset
In SMD dataset, our model achieves highest BLEU score and entity F1 score over baselines, including previous state-of-the-art result from Madotto et al. (2018).
Ablation Study
- The contributions of the global memory pointer G and the memory writing of dialogue histroy H are investigated for bABI OOv task and SMD (K=1)
 Table 5. The result of the ablation study
Table 5. The result of the ablation study
Ablation study using single hop model. Note a 0.4% increase in T5 suggests that the use of G may impose too strong prior entity probability
4 Conclusion
- This paper present end-to-end trainable model called global-to-local memory pointer networks for task-oriented dialogues.
- The global memory encoder and the local memory decoder are designed to incorporate the shared external knowledge into the learning framework.
- We empirically show that the global and the local memory pointer are able to effectively produce system responses even in the out-of-vocabulary scenario, and visualize how global memory pointer helps as well.
- As a result, our model achieves state-of-the-art results in both the simulated and the human-human dialogue datasets, and holds potential for extending to other tasks such as question answering and text summarization.